Abstract
Text-driven 3D indoor scene generation could be useful for gaming, film industry, and AR/VR applications. However, existing methods cannot faithfully capture the room layout, nor do they allow flexible editing of individual objects in the room.
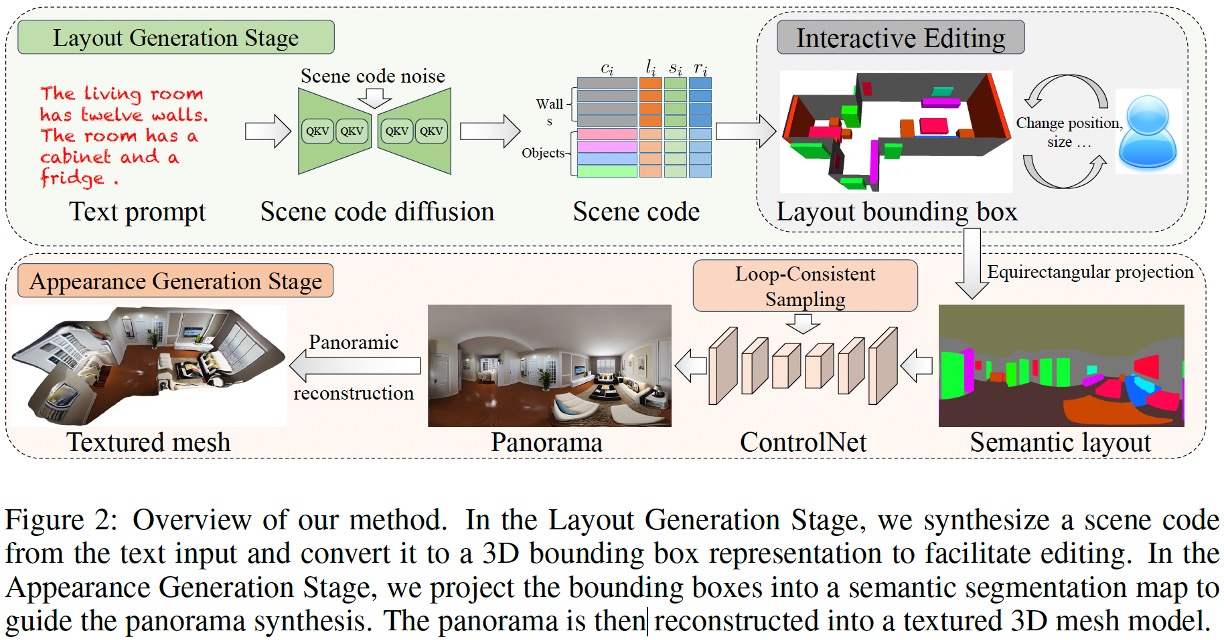
To address these problems, we present Ctrl-Room, which is able to generate convincing 3D rooms with designer-style layouts and high-fidelity textures from just a text prompt. Moreover, Ctrl-Room enables versatile interactive editing operations such as resizing or moving individual furniture items. Our key insight is to separate the modeling of layouts and appearance. Our proposed method consists of two stages, a `Layout Generation Stage' and an `Appearance Generation Stage'. The `Layout Generation Stage' trains a text-conditional diffusion model to learn the layout distribution with our holistic scene code parameterization. Next, the `Appearance Generation Stage' employs a fine-tuned ControlNet to produce a vivid panoramic image of the room guided by the 3D scene layout and text prompt.
In this way, we achieve a high-quality 3D room with convincing layouts and lively textures. Benefiting from the scene code parameterization, we can easily edit the generated room model through our mask-guided editing module, without expensive editing-specific training. Extensive experiments on the Structured3D dataset demonstrate that our method outperforms existing methods in producing more reasonable, view-consistent, and editable 3D rooms from natural language prompts.
System Overview
Panorama Generation
Comparison with state-of-the-art
We conduct extensive comparison with the state-of-the-art methods on the generated panorama.Given a simple partial-scene text prompt, our approach obtains better RGB panorama than that of Text2Light~\citep{chen2022text2light} and MVDiffusion~\citep{tang2023mvdiffusion}, which demonstrates the effectiveness of our well-designed framework. While Text2Light suffers from the inconsistent loop and unexpected content of the generated panorama, MVDiffusion fails to recover a reasonable room layout from the text prompt.



3D Room Generation
Comparison with state-of-the-art
Related Links
There's a lot of excellent work that was introduced before ours.
Text2Room introduces an iterative way to generate the 3D room mesh through 2D Diffusion Model.
Text2NeRF replaces the rigid mesh with NeRF to recover the 3D indoor scene and further expand the application into outdoor scenes.
Text2Light creates HDR panoramic images from text using a multi-stage auto-regressive generative model.
MVDiffusion proposed Correspondence-Aware mechanism to get appearance-consistent images during multi-view image generation.
BibTeX
@article{fang2023ctrl,
title={Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints},
author={Fang, Chuan and Hu, Xiaotao and Luo, Kunming and Tan, Ping},
journal={arXiv preprint arXiv:2310.03602},
year={2023}
}